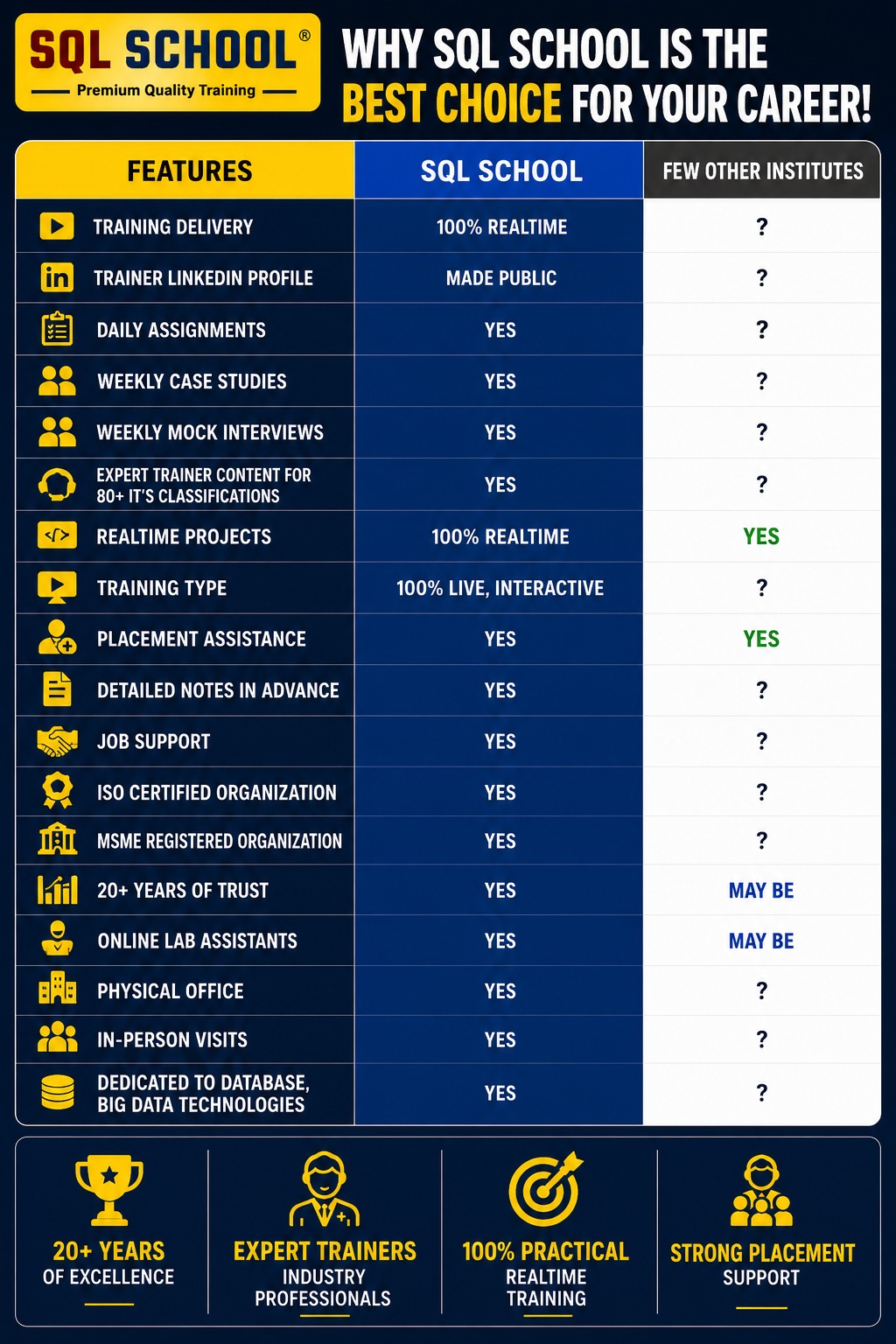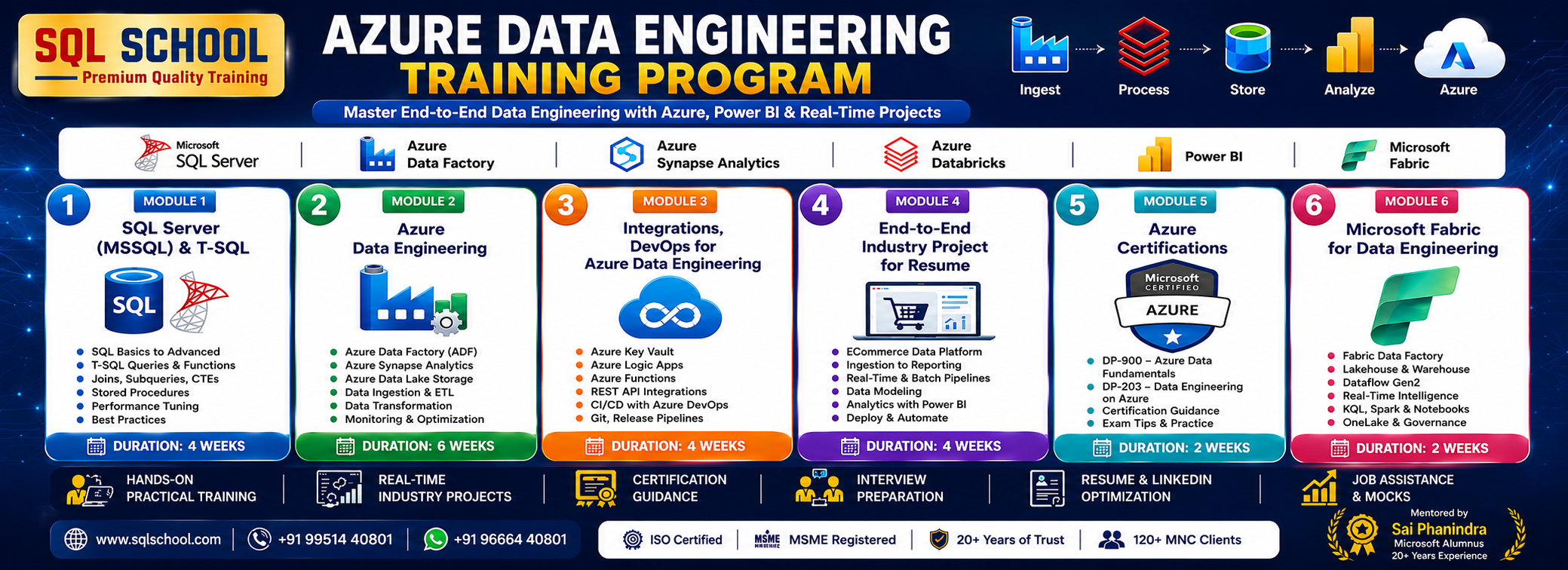


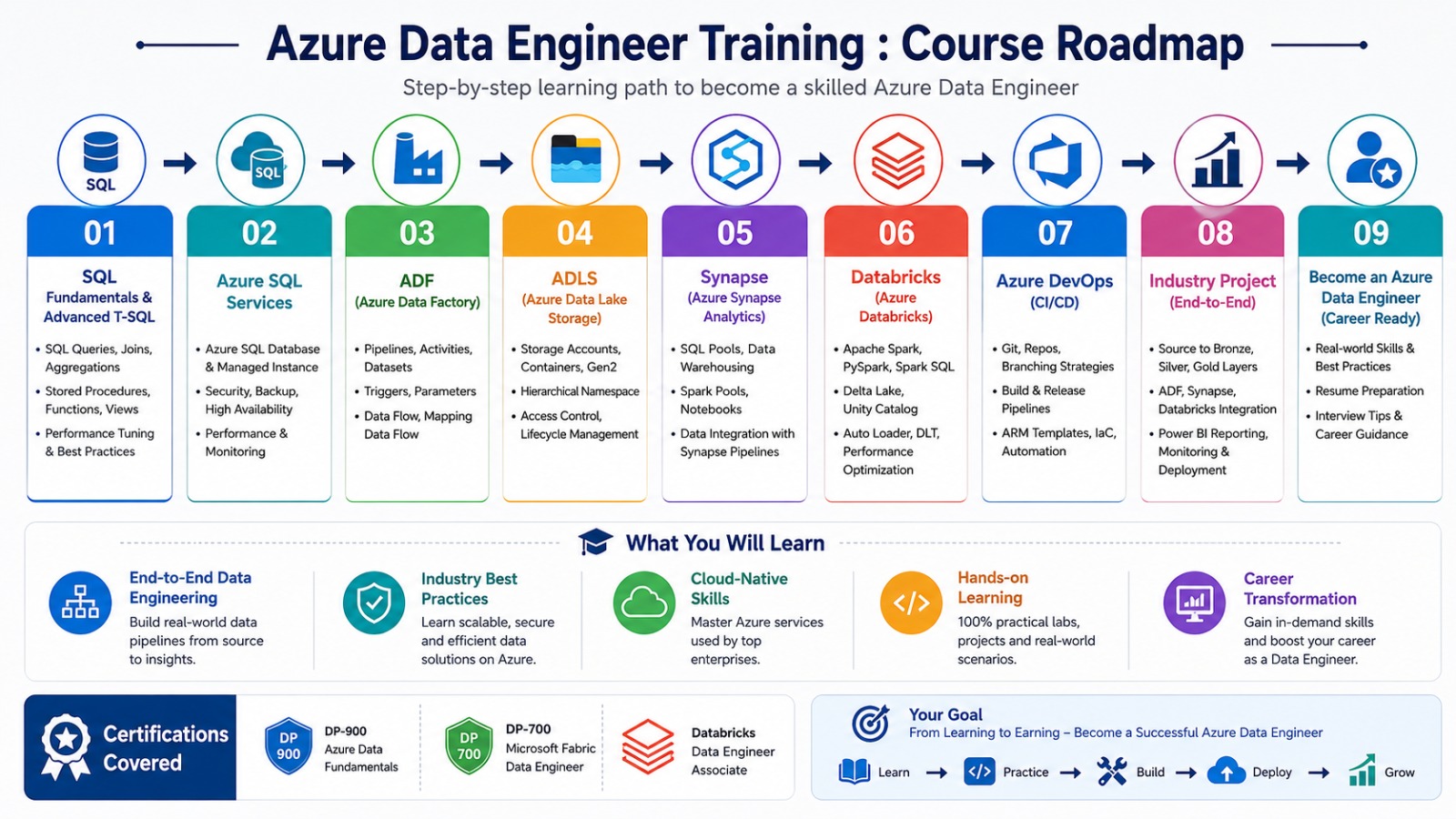

Yes. Every concept is demonstrated step-by-step with real-time scenarios, datasets, cloud resources, and complete end-to-end workflow implementation
Meet Your Trainer – Mr. Sai Phanindra
Mr. Sai Phanindra is the Chief Trainer at SQL School with 20+ years of real-world IT experience in Data Engineering, Business Intelligence, and Database Technologies. He has successfully trained thousands of professionals and helped them build successful careers in leading MNCs.
He specializes in delivering 100% practical, project-based training in:
- Microsoft Power BI
- Azure Data Engineering
- Fabric Data Engineer
- Databricks Data Engineer
- SQL Server (MSSQL & T-SQL)
- SQL Server DBA (Administration)
His training focuses on real-time projects, industry best practices, interview preparation, certification guidance, and job-ready skills to help learners confidently succeed in today’s data-driven industry.