

Databricks Data Engineer Associate focuses on building scalable data pipelines using Apache Spark and Delta Lake on Databricks. It equips you to handle ETL, data transformations, and performance optimization in cloud environments, leading to roles like Data Engineer, Spark Developer, and Cloud Data Engineer.
Training Highlights
✅Databricks Lakehouse Platform
✅Spark SQL & Delta Lake
✅ PySpark for Data Engineering
✅Medallion Architecture
✅Auto Loader & Streaming Data
✅LakeFlow & Delta Live Tables
✅Performance Optimization & Security
Modules We Learn:
✅Module 1: SQL Server TSQL (MS SQL) Queries
✅Module 2: Databricks
✅Module 3: Real Time Project (E-commerce)
Course Duration: 7 Weeks

Databricks Data Engineer Associate
Module 1: SQL Server TSQL (MS SQL) Queries
Ch 1: SQL Database Job Roles
- Introduction to Data
- Database Intro, Types
- OLTP, DWH, OLAP
- DBMS Concepts
- Database Job Roles
- Data Engineer Job Roles
Ch 2: Database Intro & Installations
- SQL Server Installations
- Instance Concepts
- Authentication Types
- Authentication Modes
- Collation & File Stream
- SQL Server 2025 Installations
- SSMS Tool Installation
- Connections, Authentications
Ch 3: SQL Basics V1 (Commands)
- Creating Databases (GUI)
- Creating Tables, Columns (GUI)
- SQL Basics (DDL, DML, etc..)
- Creating Databases, Tables
- Data Inserts (GUI, SQL)
- Basic SELECT Queries
Ch 4: SQL Basics V2 (Commands, Operators)
- DDL: Create, Alter, Drop, Add
- DML: Insert, Update, Delete
- DQL: Select, Fetch
- SQL Operators
- Special Operators
Ch 5: Excel Data Imports
- Data Imports with Excel
- SQL Native Client
- Order By: Asc, Desc
- Order By with WHERE
- TOP & OFFSET
- UNION, UNION ALL
Ch 6: Schemas & Batches
- Schemas: Creation, Usage
- Schemas & Table Grouping
- Real-world Banking Database
- 2 Part, 3 Part & 4 Part Naming
- Batch Concept & “Go” Command
Ch 7: Constraints, Keys & RDBMS
- Null, Not Null Constraints
- Unique Key Constraint
- Primary Key Constraint
- Foreign Key & References
- Default Constraint & Usage
- DB Diagrams & ER Models
Ch 8: Realtime Case Study – 1
- Medicare Database
- Patients, Visits, Meds, etc
- Keys, Constraints
- Relations, Data Validations
Ch 9: Joins & Queries
- Joins: Table Comparisons
Inner Joins & Matching Data - Outer Joins: LEFT, RIGHT
- Full Outer Joins & Aliases
- Cross Join & Table Combination
- Joining more than 2 tables
Ch 10: Views & RLS
- Views: Realtime Usage
- Storing SELECT in Views
- DML, SELECT with Views
- RLS: Row Level Security
- WITH CHECK OPTION
- Important System Views
Ch 11: Stored Procedures
- Stored Procedures: Realtime Use
- Parameters Concept with SPs
- Procedures with SELECT
- System Stored Procedures
- Metadata Access with SPs
- Stored Procedures, Tuning
Ch 12: User Defined Functions
- Using Functions in MSSQL
- Scalar Functions in Real-world
- Inline & Multiline Functions
- Parameterized Queries
- Date & Time Functions
- String Functions & Queries
- Aggregated Functions & Usage
Ch 13: Triggers & Automations
- Need for Triggers in Real-world
- DDL & DML Triggers
- For / After Triggers
- Instead Of Triggers
- Memory Tables with Triggers
- Disabling DMLs & Triggers
Ch 14: Transactions & ACID
- Transaction Concepts in OLTP
- Auto Commit Transaction
- Explicit Transactions
- COMMIT, ROLLBACK
- Checkpoint & Logging
- Lock Hints & Query Blocking
- READPAST, LOCKHINT
Ch 15: Indexes Basics, Tuning
- Indexes & Tuning
- Clustered Index, Primary Key
- Non Clustered Index & Unique
- Creating Indexes Manually
- Composite Keys, Query Optimizer
- Composite Indexes & Usage
Ch 16: CTEs & Tuning
- Common Table Expression
- Creating and Using CTEs
- CTEs, In-Memory Processing
- Using CTEs for DML Operations
- SP Recompilations
- IIF(), CASE Statement
Ch 17: Group By Queries
- Group By, Distinct Keywords
- GROUP BY, HAVING
- Cube( ) and Rollup( )
- Sub Totals & Grand Totals
- Grouping( ) & Usage
- Group By with UNION
- Group By with UNION ALL
Ch 18: Sub Queries
- Sub Queries Concept
- Sub Queries & Aggregations
- Joins with Sub Queries
- Sub Queries with Aliases
- Sub Queries, Joins, Where
- Correlated Queries
Ch 19: Joins with Group By
- Joins with Group By
- 3 Table, 4 Table Joins
- Join Queries with Aliases
- Join Queries & WHERE
- Join Queries & Group By
- Joins with Sub Queries
- Query Execution Order
Ch 20: Normal Forms & Self Joins
- Normal Forms: 1 NF, 2 NF
- 3 NF, BCNF and 4 NF
- Adding PK to Tables
- Adding FK to Tables
- Cascading Keys
- Self Referencing Keys
- Database Diagrams
Ch 21: Data Types & Variables
- Integer Data Types
- Character, MAX Data Types
- Decimal & Money Data Types
- Boolean & Binary Data Types
- Date and Time Data Types
- SQL_Variant Type
- Variables in SQL
- Cursor Variable & Fetch
Ch 22: Rank Functions, CTEs
- Window Functions (Rank)
- Row_Number( )
- Rank( ), DenseRank( )
- Partition By & Order By
- Using CTEs with Row Number
Ch 23: Merge (Upsert) with SPs
- Merge Statement
- Upsert Operations with Merge
- Merge with OLTP & DWH
- Matched and Not Matched
- Merge Statement inside SPs
Ch 24: Realtime Case Study – 2
- ECommerce Database
- Entities and ER Diagram
- Data Validations
- Query Writing
- Query Tuning
Module 2: Databricks
Ch 1: Databricks Introduction
- Cloud ETL, DWH
- Cloud Computing
- Databricks Concepts
- Big Data in Cloud
Ch 2: Databricks Architecture
- Unity Catalog, Volume
- Spark Clusters
- Apache Spark and Databricks
- Apache Spark Ecosystem
- Compute Operations
- Hadoop, MapReduce, Apache Spark
Ch 3: Unity Catalog
- Unity Catalog Concepts
- Workspace Objects
- Databricks Notebooks
- Databricks Workspace UI
- Organizing Workspace Objects
- Creating Volumes
- Spark Table Creations
- Spark UI: Limitations
Ch 4: Spark SQL: Basics
- Spark SQL Notebooks
- Creating Catalog
- Creating Schemas
- Creating Tables
- Spark Data Types
- PySpark API: SQL Queries
- Dropping Objects
- Notebooks: Exports, Clone
Ch 5: Spark SQL: Table Types
- Delta Tables
- Managed Tables
- External Tables
- Data Partitioning
- Union, Views in Spark
- External Volumes
Ch 6: Spark SQL: Functions
- Math, Sort Functions
- String, DateTime Functions
- Conditional Statements
- SQL Expressions with expr()
- Volume for our Data Assets
- File Formats, Schema Inference
- Spark SQL Aggregations
Ch 7: Spark SQL: Time Travel
- Time Travel Concepts
- Spark DB: Logical Architecture
- Spark DB: Physical Store
- Data File Store
- Log File Store
- Time Travel
- DESCRIBE, EXTENDED
- HISTORY
- Version Numbers
Ch 8: Python: Introduction, Print
- Python Introduction
- Python Versions
- Python Implementations
- Python in Spark (PySpark)
- Python Print()
- Single, Multiline Statements
Ch 9: Python: Variables
- Python Variables
- Variable Declarations
- Variable Values
- Value Types
- Multi Variable Values
- Common Variable Values
- Realtime use of Variables
Ch 10: Python: Operators
- Need for Operators
- Arithmetic Operators
- Assignment Operators
- Comparison Operators
- Operator Precedence
- Operands in Python
Ch 11: Python: Control Statements
- Python Control Structures
- If … Else Statement
- Short Hand If
- ELIF & ELSE IF Statements
- OR, AND Concepts
- Python Loops
Ch 12: Python: Data Types
- Python Data Types
- Integer / Int Data Types
- Float, String Data Types
- List Data Type
- Dictionary Data Type
- Tuple Data Type
- List Items, Indexes
- Tables Versus Dictionaries
Ch 13: Python: Modules & Dataframes
- Python Modules
- Pandas
- NumPy
- Dataframe Concepts
- Handling Nulls
- Data Cleansing Concepts
- Pandas Series, arrays
- Indexes, Indexed Lists
Ch 14: PySpark Concepts
- Constructing Dataframes
- Single List Dataframes
- Multi List Dataframes
- Pandas Dataframes
- Contact & Union
- Merge
- Join Options with Dataframes
Ch 15: Medallion Architecture – 1
- Medallion Architecture
- Aggregated Data Loads
- Broze, Silver and Gold
- Temp Views
- Spark Tables (Parquet)
- Work with File Sources
Ch 16: Medallion Architecture – 2
- Medallion Architecture
- Azure SQL DB Connections
- Joining Source Tables
- Dataframes, Temp Views
- Aggregated Data Loads
- Gold Data Consumption
Ch 17: Delta Lake
- Databricks DeltaLake
- Schema Evolution
- Azure SQL DB Connections
- Dataframes, Temp Views
- Delta Table API
- Deleting Records
- Updating Records
- Merging Records
- Old History Retention
- Delta Transaction Log
Ch 18: PySpark: Widgets
- PySpark Parameters
- Text Widgets
- User Parameters
- Manual Executions
- Automations
- UI & JSON For Widgets
Ch 19: Lake Flow Jobs
- Worksflows & CRON
- Job Compute, Running Tasks
- Python Script Tasks
- Parameters into Notebook Tasks
- Parameters into Python Script Tasks
- Concurrent Executions, Dependencies
- Branching Control with the If-Else Task
Ch 20: Pyspark: Auto Loader – 1
- AutoLoader Concept
- Cloudfiles Architecture
- Checkpoint Configurations
- Creating Directories
- Reading Databricks Cloud Sources
- Initial Loads
Ch 21: PySpark: Auto Loader – 2
- Reading Streams with Auto Loader
- Reading a Data Stream
- Manually Cancel your Data Streams
- Writing to a Data Stream
- Schema Evaluation Modes
- Adding New Columns
- Workspace Modules
Ch 22: Lake Flow Declarative Pipelines
- SDP: Spark Declarative Pipelines
- Delta LIVE Tables
- Streaming Data Loads
- Bronze, Silver, Gold Data
- Materialized Views
- Pipeline Clusters
- Databricks CLI
- Data Quality Checks
Ch 23: Databricks Optimizations
- Lazy Evaluation
- Explain Plan
- Caching
- Data Shuffling
- Broadcast Joins
- Partitions
- Data Skipping
- Z Ordering
- Liquid Clustering
- VACUUM
- OPTIMIZE
Ch 24: Security Concepts
- Overview of ACLs
- Adding a New User to Workspace
- Workspace Access Control
- Cluster Access Control
- Groups & LakeBridge
- Access Keys (Tokens)
Ch 25: Version Control & GitHub
- Local Development
- Runtime Compatibility
- Git and GitHub Pre-requisites
- Git and GitHub Basics
- Linking to GitHub & Databricks
- Databricks Git Folders
- Project Code to GitHub
- Adding Modules to the Project Code
- Databricks Job Updates, Runs
Ch 26: Databricks Data Engineer Associate Exam
- Databricks Data Engineer Associate Exam
- AVRO Formats
- Exam Guidance
- Databricks Exam Pattern
- Exam Q & A, Scenarios
Module 3: Real Time Project (E-commerce)
Realtime Project : (E-commerce Platform)
Project Objective
Build an end-to-end Azure Data Engineering solution to process, transform, and analyze ecommerce business data from multiple sources.
Technologies Used
- Spark
- SparkSQL
- Python ETL
- PySpark
- Unity Catalog
- SDP
- Delta LIVE Tables
- Auto Loader
- Optimizations
Skills Gained
- Data Ingestion & ETL Development
- Azure Data Factory Pipelines
- Databricks & PySpark Transformations
- Data Lake Architecture
- Medallion Architecture (Bronze/Silver/Gold)
- Real-Time Industry Experience
Module 4: Databricks Data Engineer Associate Exam Guidance
Databricks Data Engineer Associate exam guidance
1. Databricks Intelligence Platform
- Know the difference between Delta Lake, Unity Catalog, and Lakehouse architecture for MCQs.
- Memorize when to use all-purpose clusters vs job clusters vs serverless compute.
- Understand which platform features handle query optimization and data layout automatically.
- Be clear on the role of Databricks workspace, metastore, and catalog in the platform hierarchy.
- Expect 1–2 questions on platform value and use-case-based compute selection.
2. Data Ingestion and Loading
- Know when to use Auto Loader vs COPY INTO vs Lakeflow Connect — this is a high-frequency topic.
- Remember Auto Loader supports schema inference, enforcement, and evolution out of the box.
- COPY INTO is idempotent and best for one-time or scheduled batch loads from cloud storage.
- Lakeflow Connect is used for enterprise connectors; know standard vs managed connector differences.
- Expect scenario-based questions asking you to pick the right ingestion method for given requirements.
3. Data Transformation and Modeling
- Know Medallion Architecture layers (Bronze/Silver/Gold) and the purpose of each — guaranteed in exam.
- Practice PySpark aggregation functions: groupBy, count, countDistinct, sum, mean.
- Understand join types — especially when broadcast join is preferred for performance.
- Know DDL vs DML commands: CREATE OR REPLACE, INSERT INTO, MERGE INTO syntax.
- Expect code-based MCQs asking you to identify correct PySpark or SQL syntax.
4. Lakeflow Jobs and Pipeline Orchestration
- Understand DAG-based task dependencies and how tasks are linked in Lakeflow Jobs.
- Know trigger types — scheduled, file arrival, table update — and when each is appropriate.
- Remember repair run allows restarting only failed tasks, not the full pipeline.
- Know how to set retries, timeouts, and conditional branching inside a job.
- Expect questions on serverless compute benefits and job monitoring via run history view.
5. CI/CD and Deployment
- Know what Declarative Automation Bundles (DAB) are and how they differ from manual deployment.
- Understand bundle structure: targets (dev/test/prod), variables, and overrides.
- Remember Databricks CLI commands are used to validate and deploy bundles in CI/CD pipelines.
- Know Git-based workflow in Databricks — branching, commit, push, and pull request steps.
- Expect 2–3 questions on promoting pipelines across environments using DAB.
6. Governance, Security, and Data Quality
- Know the Unity Catalog hierarchy: Metastore → Catalog → Schema → Table — frequently tested.
- Memorize GRANT/REVOKE/DENY syntax and which privileges apply at which hierarchy level.
- Understand managed vs external tables — storage location, ownership, and drop behavior differ.
- Know column masking and row-level security concepts for restricting data by user group.
- Expect questions on Delta Sharing, lineage tracking, and audit log storage in Unity Catalog.

What is the Databricks Data Engineer Associate Training?
This training covers Databricks concepts end-to-end including Spark SQL, PySpark, Delta Lake, Lakehouse, Auto Loader, DLT, Unity Catalog, Workflows, Streaming, Medallion Architecture, and Real-Time Projects.
Who should join this course?
Aspiring Data Engineers, Cloud Engineers, BI Developers, Data Science Engineers, and freshers who want to build a strong career in Databricks and modern Data Engineering.
What modules are included in this training?
Module 1: MSSQL
Module 2: Python
Module 3: Databricks (Complete)
Module 4: Databricks Data Engineer Associate Exam Guidance
Is SQL included as part of the training?
Yes. SQL Server basics to advanced topics including DDL, DML, Joins, Constraints, Keys, Views, Procedures, Functions, CTEs, Tuning, Indexes, Group By, Subqueries, Transactions, and Window Functions.
Do I need Python knowledge to learn Databricks?
Yes, and this course teaches Python from scratch including data types, loops, functions, modules, file handling, exception handling, and full pandas for ETL.
What Databricks basics will I learn?
You will learn Workspace, Notebooks, Clusters, Filesystems, Catalogs, Schemas, and Databricks Architecture including Spark and Lakehouse fundamentals.
Does the course include Spark SQL?
Yes. Spark SQL API, creating schemas, altering columns, unions, math functions, sort functions, string functions, date/time functions, conditional logic, expr() and complex SQL expressions.
Will I learn PySpark in detail?
Yes. Creating DataFrames, reading/writing CSV/JSON/ORC/Parquet, schema inference, grouping, filtering, joins, union, pivot/unpivot, transformations, and rendering outputs.
Is Unity Catalog included in the curriculum?
Yes. Managed tables, external tables, volumes, catalogs, schemas, views, access control, workspace binding, lineage, metastore, system tables, and securable objects.
Will I learn Data Ingestion & Auto Loader?
Yes. Auto Loader streaming ingestion, schema inference, evolution, streaming reads/writes, cancellations, and workspace modules.
Is Medallion Architecture taught?
Yes. Bronze, Silver, Gold layers, aggregated loads, temp views, parquet tables, file/table sources, and building reliable pipelines using Medallion principles.
What Delta Lake concepts does this course cover?
Delta Table API, delete/update/merge, time travel, history, schema evolution, DML operations, retention, transaction logs, and Delta Lake SCD Type 2 implementation.
Will I learn SCD Type 2 in real-time?
Yes. Incremental loads, new/existing record handling, history retention, upserts, and automation using Delta Lake and notebooks.
Does the course include Streaming & Structured Streaming?
Yes. Streaming simulations, micro-batches, schema evolution, watermarking, time-based aggregations, triggers, and Delta streaming pipelines.
Do you cover Databricks Workflows (Jobs)?
Yes. Jobs scheduling, CRON, task dependencies, branching logic, passing parameters into notebooks/py scripts, concurrent executions, and job clusters.
Is Databricks Tuning part of the training?
Yes. Explain plans, lazy evaluation, caching, data shuffling, broadcast joins, partitioning, data skipping, Z-ordering, Liquid Clustering, and Spark configs.
Will I learn GitHub Integration?
Yes. Git prerequisites, linking GitHub with Databricks, Git folders, adding modules, version control, code sync, and pipeline updates.
Does the course include Delta Live Tables (DLT)?
Yes. Pipeline clusters, Data Quality checks, declarative pipelines, streaming datasets, parameterization, and DLT streaming live tables.
Is a real-time project included?
Yes. E-Commerce/Banking/Sales projects with requirements, solutions, FAQs, architecture flow, interview questions, and resume guidance.
Is exam preparation for Databricks Data Engineer Associate included?
Yes. Exam guidance, sample questions, mock exams, and hands-on practice for the certification.


SQL SCHOOL vs Other Institutes
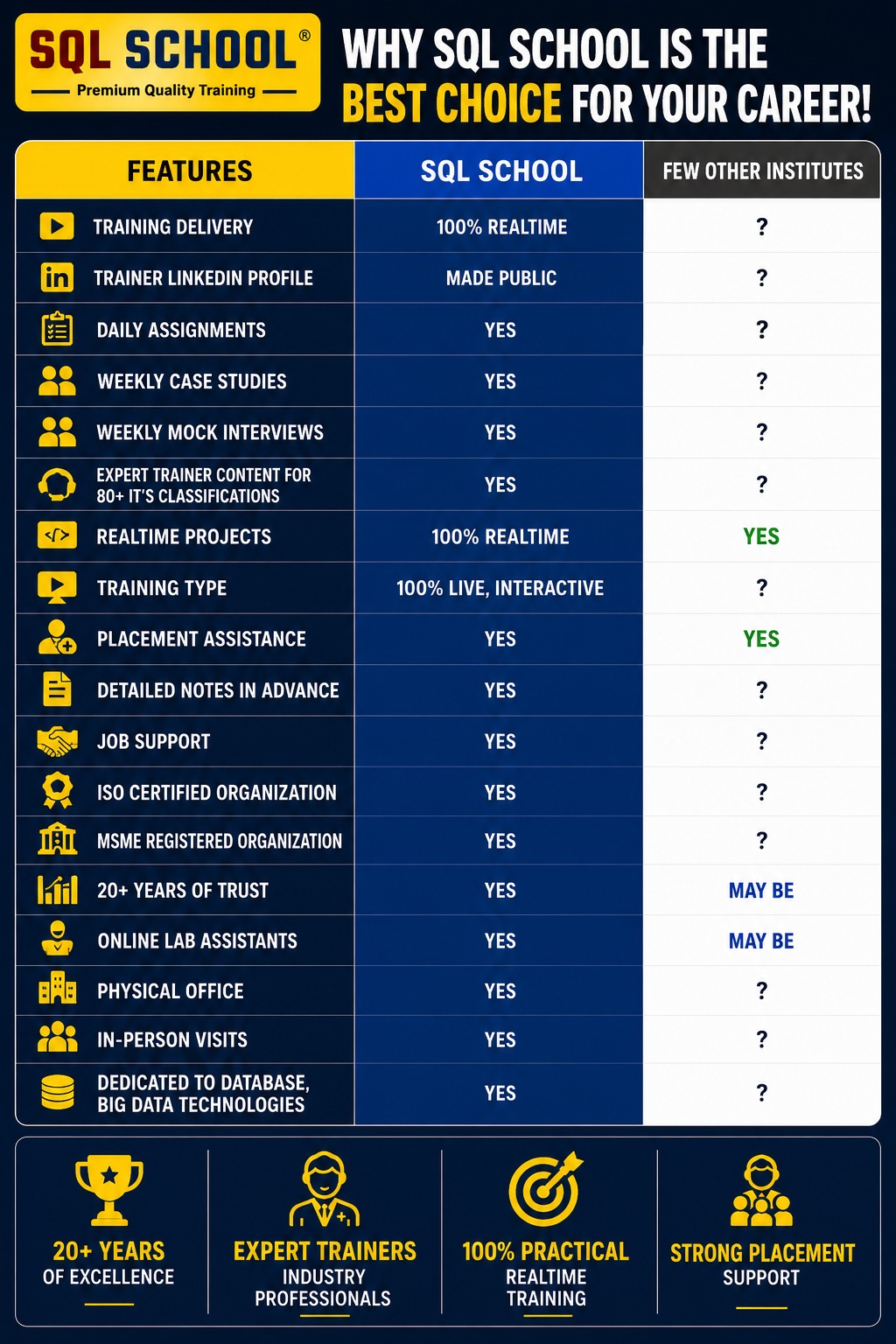

Placement Partners

























SQL SCHOOL
24x7 LIVE Online Server (Lab) with Real-time Databases.
Course includes ONE Real-time Project.
Why Choose SQL School

- 100% Real-Time and Practical
- ISO 9001:2008 Certified
- Weekly Mock Interviews
- 24/7 LIVE Server Access
- Realtime Project FAQs
- Course Completion Certificate
- Placement Assistance
- Job Support











